You might have noticed that at times, it appears that IIS6 is losing or dropping your ASP.net session information. After looking around under the hood of IIS, there are a couple settings in IIS6 which can affect the consistency of session data.
In case you’re not already aware, IIS has two different mechanisms to handle ASP.net session information:
If your ASP.net site utilises out of process session management, then you really don’t have a lot to worry about. If on the other hand your site utilises the default configuration, which is in process management, then you have some important points to be aware of.
Application Pools
One of the new options within IIS6 is a feature called an application pool. An application pool is a way to isolate a web site or collection of, from other web sites. This isolation is created by each application pool having its own worker processes. Of course, if you’re using in process session management then each application pools session data is also isolated from another.
For convenience, a virtual host in IIS6 can contain as more than one application within it. If you are not aware of the impact of creating applications, then it is very simple for your ASP.net site to be serviced by more than one worker process. Of course, when that happens and a clients request is bounced between multiple worker processes; their session data is ‘lost’ for the first request in each process. From that point onwards, it exists however updating a session object in one process does not update it in the other, leading to inconsistent application execution.
Web Garden
A web garden is a small scale web farm (har har!) which allows multiple worker processes to service a single application pool on the same server. Since each worker process has its own memory for storing session information, you’ll run into issues using a web garden and in process session management at the same time.
Recycling Processes
IIS also provides a convenient way of recycling worker processes systematically. A lot of web hosts will use this feature to cycle processes daily in the early hours of the morning to keep the memory use of each worker process to a minimum. Of course, if you’re application is using in process management – this feature would destroy any active session data being stored. This might seem trivial, however it would be extremely frustrating to have a worker process automatically cycle while you were half way through filling up your online shopping cart.
Simple Solutions
If you happen to have multiple applications running within a single site, you can force each application to use the same application pool. By doing so, each application will be served by the same worker process (assuming you are not using a web garden) and thus all of your applications can share session information seamlessly.
If you’re using a web garden at the moment and you’re application doesn’t receive enough load to require the other worker processes, reducing it back to a single process will stop you ‘losing’ session information. If you require the other worker processes, then you don’t have a choice but to use an out of process storage mechanism. If you don’t want to use the state server or SQL Server, you could alternatively roll your own as well.
Unfortunately, if you’re using in process session storage you don’t have a leg to stand on when a worker process is recycled. If you are using any out of process mechanism, either the two listed above or your own custom version – you should find that your session information is perfectly safe whilst cycling processes.
Happy session management!
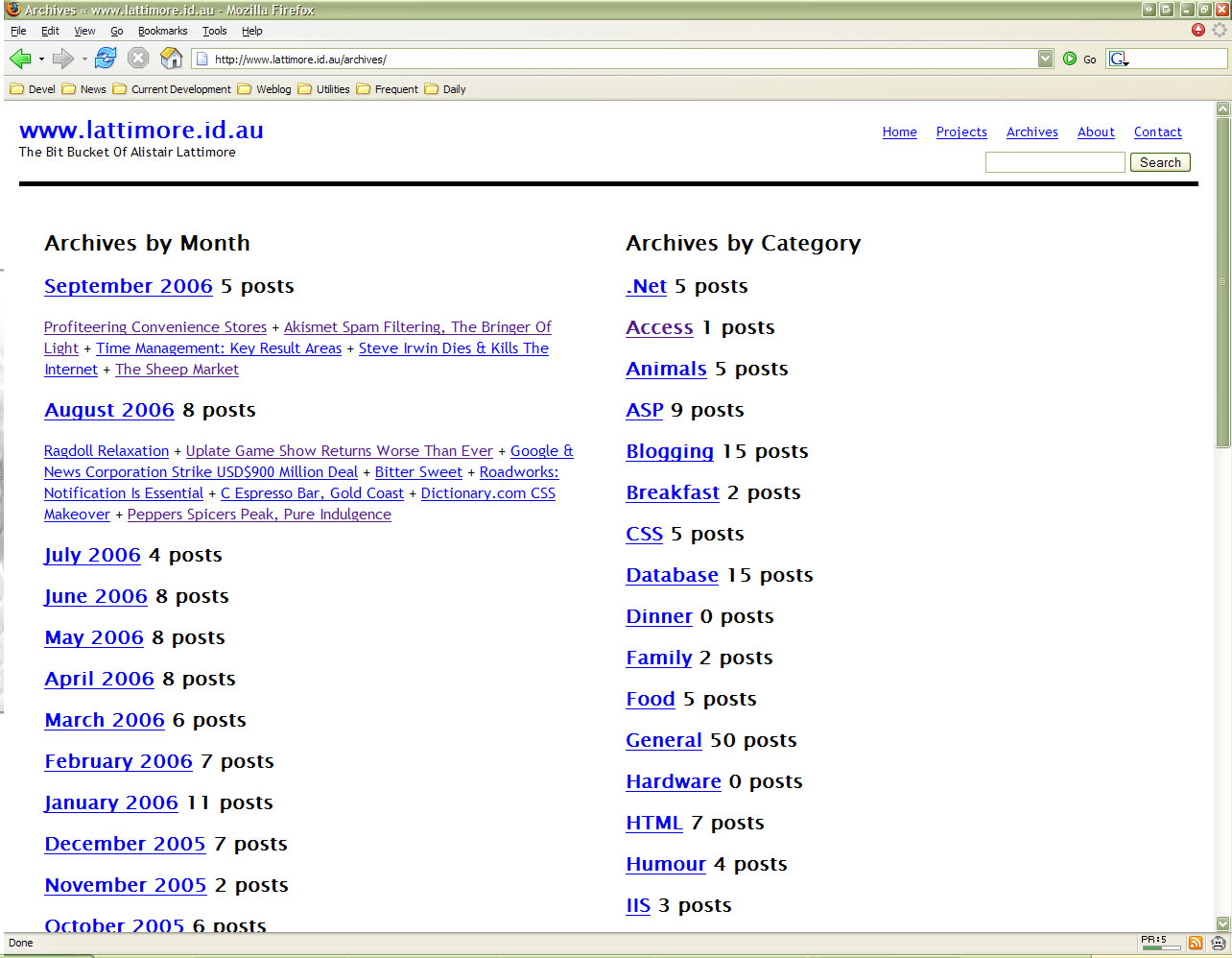 Looking for a new way to display your WordPress archives page? Look no further, you’ve found the Subtraction Style Archives plugin. The Subtraction Style Archives plugin provides functionality which will allow you to generate an archive page similar to that on Subtraction.
Looking for a new way to display your WordPress archives page? Look no further, you’ve found the Subtraction Style Archives plugin. The Subtraction Style Archives plugin provides functionality which will allow you to generate an archive page similar to that on Subtraction.